Compressed-Sensing Recovery of Multiview Image and Video Sequences using Signal Prediction
M. Trocan, E. W. Tramel, J. E. Fowler, & B. Pesquet-Popescu
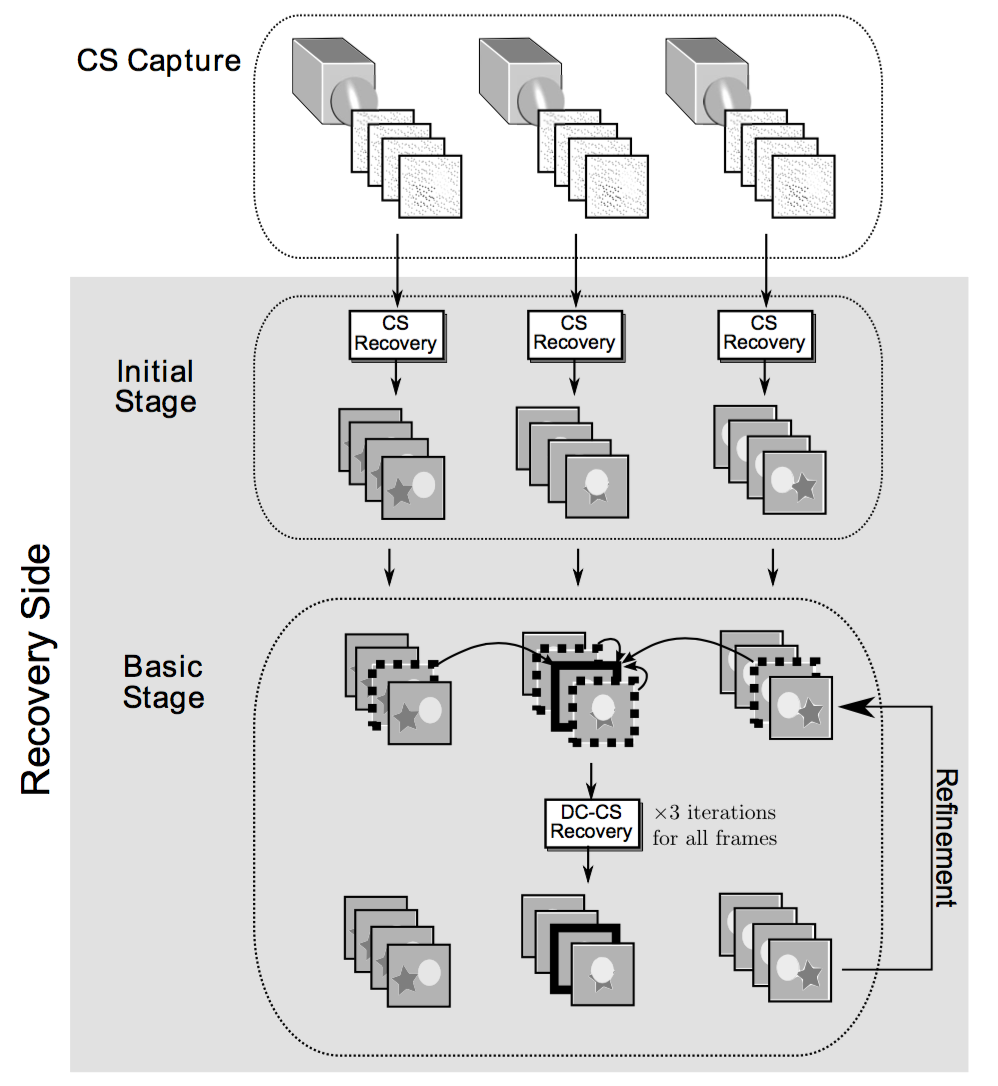
Astract
In the compressed sensing of multiview images and video sequences, signal prediction is incorporated into the reconstruction process in order to exploit the high degree of interview and temporal correlation common to multiview scenarios. Instead of recovering each individual frame independently, neighboring frames in both the view and temporal directions are used to calculate a prediction of a target frame, and the difference is used to drive a residual-based compressed-sensing reconstruction. The proposed approach demonstrates a significant gain in reconstruction quality relative to the straightforward compressed-sensing recovery of each frame independently of the others in the multiview set, as well as a significant performance advantage as compared to a pair of benchmark multiple-frame compressed-sensing reconstructions.
BibTeX
article{ttf2014,
Author = {Maria Trocan and Eric W. Tramel and James E. Fowler and Beatrice Pesquet-Popescu},
Journal = {Multimedia Tools and Applications},
Pages = {1-27},
Title = {Compressed-Sensing Recovery of Multiview Image and Video Sequences using Signal Prediction},
Year = 2014}
Related Posts
- Increasing acceptance of AI‐generated digital twins through clinical trial applications
- Digital twin generators for disease modeling
- Boosting Clinical Trial Power in Parkinson's disease (PD) with AI-Generated Digital Twins
- Semi-supervised federated learning for keyword spotting
- Federated learning for predicting histological response to neoadjuvant chemotherapy in triple-negative breast cancer