CUDA Perceptron in 2008
After I finished by B.S. in Computer Engineering, my thought was to take a quick two year extension into a Masters degree, just for pure marketability before getting into the job market. I hadn’t yet gotten the itch for research, and I wasn’t keenly invested into the state of machine learning at the time. However, I had previously run projects for both image classification using neural-networks, and as a side-project, a friend and I attempted to train an NN for stock prediction – a hopeless task, but at least one which was pretty educational.
Further, because of my original intent in pursuing game-engine architecture, I had spent some time studying both OpenGL, and had become familiar with the concept of general-purpose GPU computing. This was novel at the time – ATI and Nvidia had made these great machines for running graphics pipelines, but their other purposes had only just started to hit the scientific computing scene.
HPC researchers were at the time writing custom graphics code to render bizzaro images as a way to hack their general programs into GPUs. Nvidia, in a stroke of brilliance, capitalized on this growing niche with the release of CUDA in 2006. CUDA made the implementation of such general algorithms so much smoother, and started the march of tooling that arrived at the general state of AI computing today.
I wanted to wed together these two interests, so in 2007-2008 I sought to write neural-network computations on the GPU. Initially I didn’t have a concept for implementing the efficient training of NNs, however my first pass was focused on accelerating inference on MLPs. However, I believe one of the first references was Oh & Jung’s 2004 publication GPU Implementation of Neural Networks for text classification. Like my own junior effort, this paper nowhere describes how to train such a network, but the promise was certainly there.

Later, and more notably, Ng and students published on efficient DBN training on GPU in 2009. But I think maybe the prize goes to Chellapilla, Puri, and Simard with their 2006 work High Performance Convolutional Neural Networks for Document Processing, which implemented both forward and back-prop to permit full CNN training on the GPU to great effect. Perhaps their only sin with respect to the arc of history was to achieve a mere 3x speedup versus the 70x that Raina, Madhavan, and Ng would report a few years later. Perhaps there was a bitter lesson there – Ng et all opted for a then-refined CUDA + GPU setup versus the pixel & vertex shader programming on ATI cards that netted Chellapilla et al such a modest gain.
However, at the time, I was unaware of these developments. As I said, I had no introduction to research practice at this point in 2007-2008. It is now a funny artifact of history that I can see that I had stumbled into a topic that was really bleeding edge, and would later have a huge impact on the world with Krizhevsky, Sutskever, and Hinton’s AlexNet moment in 2012.
While I was able to get running on CUDA and got some nice speedups on MLP inference, I didn’t pursue the topic and dropped it. Why?
- Funding. At the time, the professor I was working with offered me no funding whatsoever, and was willing to just take me on as a kind of self-funded student. I had some TA work, but this was a really bad setup for my personal situation.
- Lack of Mentorship. MSU didn’t really have anyone working on these ML topics or really involved in the community at the time – which is why even if I had continued, I would have missed the entire wave. Having connections within an active area of research is critical, and my impromptu-not-quite-advisee-and-no-funding situation didn’t help.
- Too Early For Impact. Again, one needs to think about the timing. Speedups end-to-end training speedups on GPU were demonstrated in 2006 and 2009. However, the “AlexNet Moment” didn’t occur until 2012. The reasons for this are probably long, but the main one was that we just did not have access to the kinds of datasets which would permit effective ML training at a useful scale. AlexNet was only possible owing to Fei-Fei Li and the ImageNet dataset. Prior to that, while one could attempt to bring together a lot of data to demonstrate the possibility of training neural networks (e.g. Lecun with MNIST), there was no practical day-to-day utility in it since no organization was undertaking that or had access to such data readily. The world was not yet “ML Ready”. Further, it meant that at the time, there were no public demonstrations of the utility of NNs in the zeitgeist at all – in fact one of my CS professors pointedly told me this field of research was entirely dead.
As further evidence of how early the concept of ML on GPU was at this point, take a look at this April 2008 article on CUDA based on interviews with David Kirk, then Nvidia’s Chief Scientist. While there is a great discussion of the architecture of Nvidia chips, CUDA, and the utility for wide-ranging applications, what isn’t there is a single mention of pattern recognition, machine learning, AI, etc.
Experiments
Doing a bit of self-archaeology, I was able to come up with at least a little bit of information about this project. From the schematic below, it seems like I was taking a look at the implementation of just a single linear layer with an activation function \(y = f(W x)\).
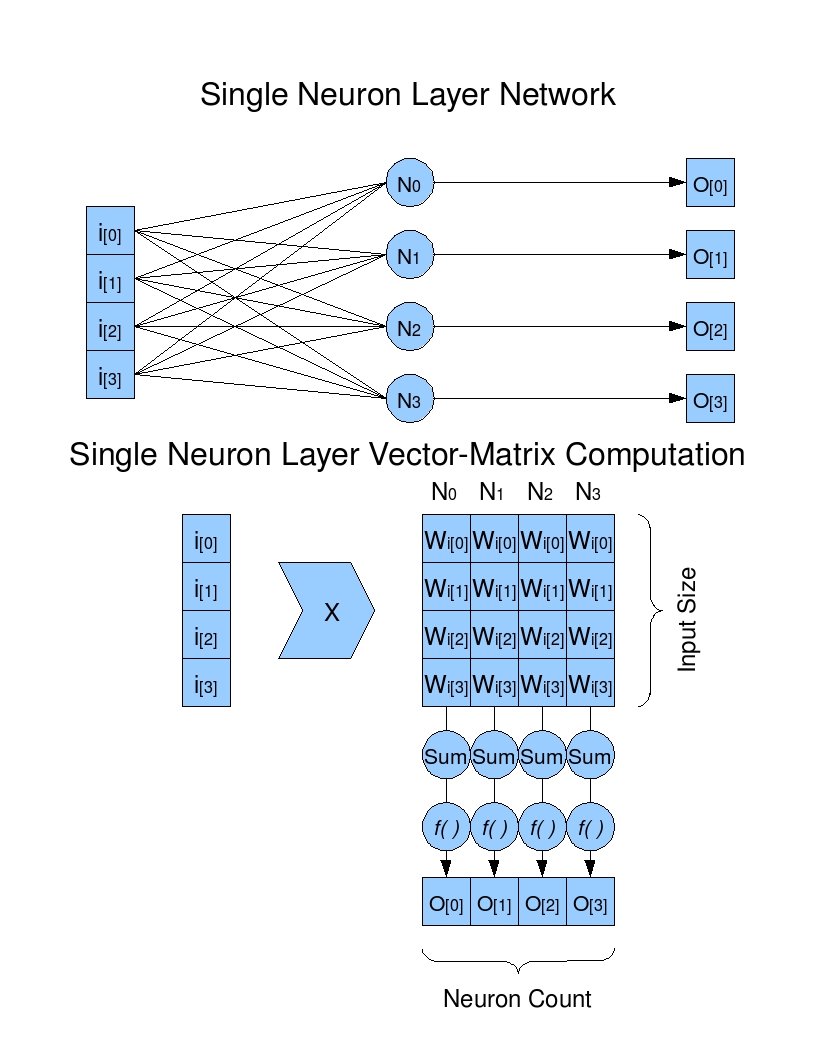
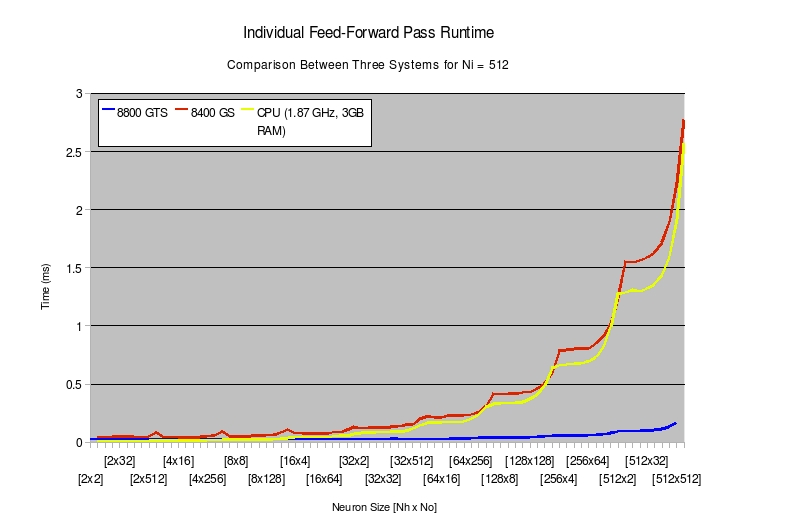
The game of this experiment is to see where the advantage of GPU computation comes in for this simple operation. To test this, it seems like I had three possible options,
- A <2Ghz Intel CPU. What a time we lived in.
- An 8400GS. This card had 256MB @ ~400Mhz – purportedly able to hit 29.38 GFlops.
- An 8800 GTS. This card had 320MB @ ~500Mhz, but more parallel compute, clocking in at about 10x the compute throughput, ~228 GFlops.
Scaling up architecture dimensionality, we see an interesting comparison curve.
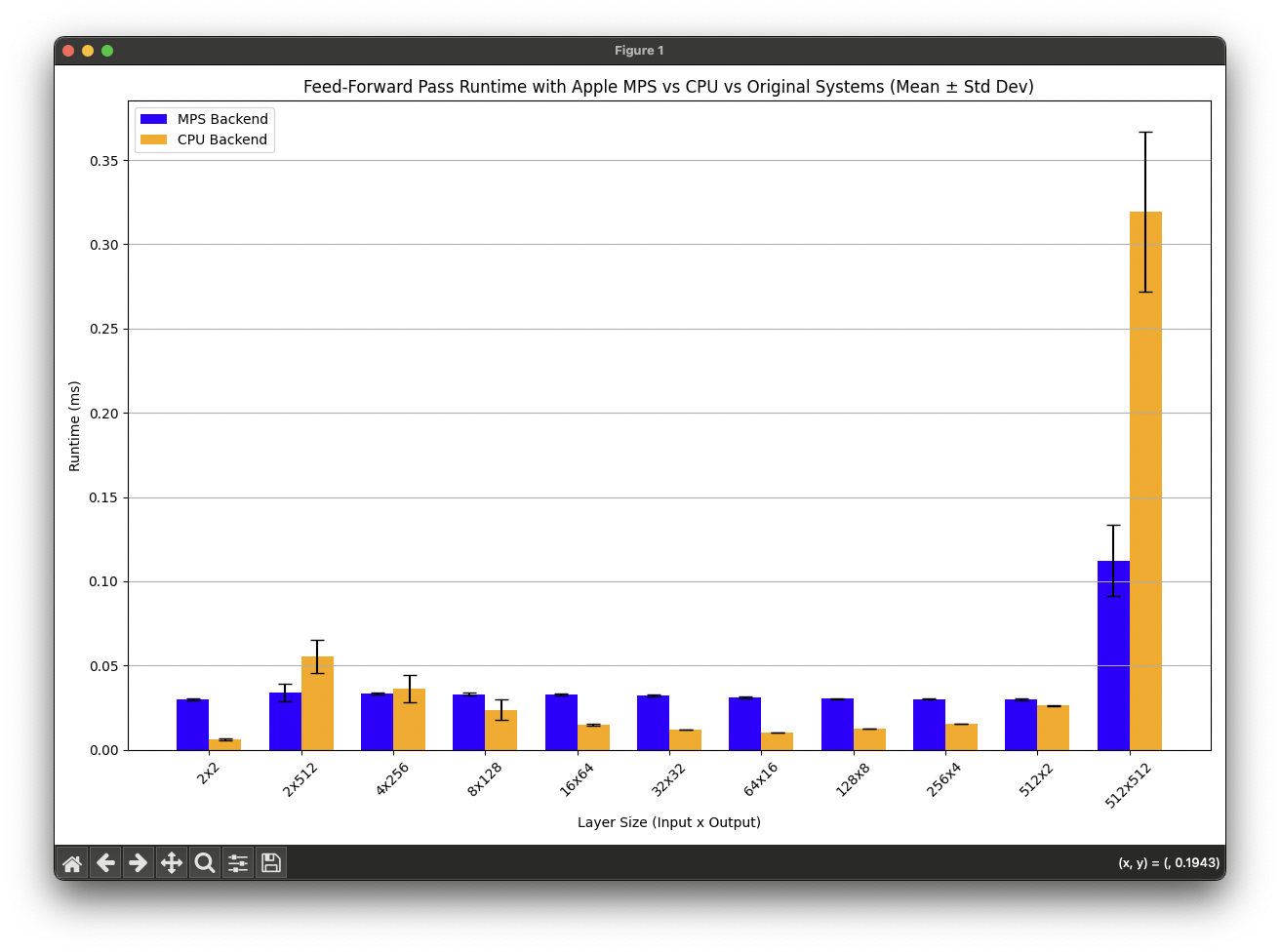
I wanted to understand just how this level of performance compares to today’s consumer hardware. Below, I made a quick comparison for the same experiment, but this time running it on the Apple Silicon M4 chip (a Q4 2024 Macbook). Here, the implementation was done using a simple PyTorch model.
2008 Implementation
For posterity, here you can see what programming NNs looked like at the time and count your blessings.
Main
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
/***************************************************************************
CUDATest: This application is meant to be a simple test bench to play with
kernel code for CUDA.
Author: Eric Tramel, MSU
***************************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
#include <cutil.h>
#include <ctype.h>
#include "template_kernel.cu"
//#define PAUSE
#define CHECK_OUTPUT
#define NUMBER_RUNS 10
#define PASS_COUNT 300
const int DESIRED_RES = INPUT_COUNT*HIDDEN_LEVEL_NEURON_COUNT;
const int hiddenLevelWeightingMatrixSize = INPUT_COUNT * HIDDEN_LEVEL_NEURON_COUNT;
const int outputLevelWeightingMatrixSize = HIDDEN_LEVEL_NEURON_COUNT * OUTPUT_LEVEL_NEURON_COUNT;
float minf(float a, float b){
float out = a;
if(b < a)
out = b;
return out;
}
float maxf(float a, float b){
float out = a;
if(b > a)
out = b;
return out;
}
void displayVector(float* vector, int length){
int i;
for(i = 0; i < length; i++){
printf("[%d]: %f\n",i,vector[i]);
if(i%15 == 0 && i != 0)
getchar();
}
}
void displayMatrix(float* matrix, int cols, int rows){
int row, col;
for(row = 0; row < rows; row++){
for(col = 0; col < cols; col++){
printf("[%d][%d]: %f ",col,row,matrix[rows*col + row]);
}
printf("\n");
}
}
void displayActivationLevels(float* matrix, int cols, int rows){
int col;
for(col = 0; col < cols; col++){
printf("Neuron #%d Level: %f\n",col,matrix[col*rows]);
}
}
int main(int argc, char **argv){
unsigned int hTimer;
unsigned int counter;
unsigned int runCount;
float* h_inputVector;
float* h_hiddenLevelWeightingMatrix;
float* h_hiddenToOutputBuffer;
float* h_outputLevelWeightingMatrix;
float* h_outputVector;
unsigned int* h_hiddenLevelFinishedFlag;
float* d_inputVector;
float* d_hiddenLevelWeightingMatrix;
float* d_hiddenToOutputBuffer;
float* d_outputLevelWeightingMatrix;
float* d_outputVector;
unsigned int* d_hiddenLevelFinishedFlag;
float totalTime = 0;
float currentTime = 0;
float minTime = 99999;
float maxTime = 0;
unsigned int totalErrorCount = 0;
srand(123);
CUT_DEVICE_INIT();
for(runCount = 0; runCount < NUMBER_RUNS; runCount++){
unsigned int localError = 0;
//Allocating CPU memory for the input vector and the weighting matrix
//
#ifdef PAUSE
printf("Allocating Host Memory\n");
#endif
h_inputVector = (float *)malloc(sizeof(float) * INPUT_COUNT);
h_hiddenLevelWeightingMatrix = (float *)malloc(sizeof(float) * hiddenLevelWeightingMatrixSize);
h_hiddenToOutputBuffer = (float *)malloc(sizeof(float) * HIDDEN_LEVEL_NEURON_COUNT);
h_outputLevelWeightingMatrix = (float *)malloc(sizeof(float) * outputLevelWeightingMatrixSize);
h_outputVector = (float *)malloc(sizeof(float) * OUTPUT_LEVEL_NEURON_COUNT);
h_hiddenLevelFinishedFlag = (unsigned int *)malloc(sizeof(unsigned int));
//Allocating the same amount of memory in our GPU Global memory
//
#ifdef PAUSE
getchar();
printf("Allocating Device Memory\n");
#endif
cudaMalloc((void**)&d_inputVector, sizeof(float) * INPUT_COUNT);
cudaMalloc((void**)&d_hiddenLevelWeightingMatrix, sizeof(float) * hiddenLevelWeightingMatrixSize);
cudaMalloc((void**)&d_hiddenToOutputBuffer, sizeof(float) * HIDDEN_LEVEL_NEURON_COUNT);
cudaMalloc((void**)&d_outputLevelWeightingMatrix, sizeof(float) * outputLevelWeightingMatrixSize);
cudaMalloc((void**)&d_outputVector, sizeof(float) * OUTPUT_LEVEL_NEURON_COUNT);
cudaMalloc((void**)&d_hiddenLevelFinishedFlag, sizeof(unsigned int));
//Intialize our memory space for the input vector and the weighting matrix on the
//host system (CPU). Note: We are storing a matrix within a vector (an array). The
//reason for this is because, at least with my own capability with CUDA, handling
//arrays are much simpler than real two-dimensional objects on the device memory.
//Dealing with such objects requires using Pitches, etc.
//Storage Method: Column by column => [0],[1],[2],...,[INPUT_COUNT] is the first COLUMN
//of our matrix. Immediate after this is the NEXT COLUMN, and so on.
//
#ifdef PAUSE
getchar();
printf("Initializing Input Vector\n");
#endif
for(counter = 0; counter < INPUT_COUNT; counter++){
h_inputVector[counter] = 1.0;
}
#ifdef PAUSE
getchar();
printf("Initializing Hidden Matrix\n");
#endif
for(counter = 0; counter < hiddenLevelWeightingMatrixSize; counter++){
h_hiddenLevelWeightingMatrix[counter] = 1.0;
}
#ifdef PAUSE
getchar();
printf("Initializing Buffer\n");
#endif
for(counter = 0; counter < HIDDEN_LEVEL_NEURON_COUNT; counter++){
h_hiddenToOutputBuffer[counter] = 0.0;
}
#ifdef PAUSE
getchar();
printf("Initializing Output Matrix\n");
#endif
for(counter = 0; counter < outputLevelWeightingMatrixSize; counter++){
h_outputLevelWeightingMatrix[counter] = 1.0;
}
#ifdef PAUSE
getchar();
printf("Initializing Output Vector\n");
#endif
for(counter = 0; counter < OUTPUT_LEVEL_NEURON_COUNT; counter++){
h_outputVector[counter] = 0.0;
}
#ifdef PAUSE
getchar();
printf("Initializing Flag\n");
#endif
*(h_hiddenLevelFinishedFlag) = (unsigned int)0;
//Copying the input vector and weighting matrix into the allocated device global memory
// cudaMemcpy(d_matrix, h_matrix, matMem, cudaMemcpyHostToDevice)
#ifdef PAUSE
getchar();
printf("Copying Host Memory to Device Memory\n");
#endif
cudaMemcpy(d_inputVector, h_inputVector, sizeof(float) * INPUT_COUNT, cudaMemcpyHostToDevice);
cudaMemcpy(d_hiddenLevelWeightingMatrix,h_hiddenLevelWeightingMatrix, sizeof(float) * hiddenLevelWeightingMatrixSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_hiddenToOutputBuffer, h_hiddenToOutputBuffer, sizeof(float) * HIDDEN_LEVEL_NEURON_COUNT, cudaMemcpyHostToDevice);
cudaMemcpy(d_outputLevelWeightingMatrix,h_outputLevelWeightingMatrix, sizeof(float) * outputLevelWeightingMatrixSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_outputVector, h_outputVector, sizeof(float) * OUTPUT_LEVEL_NEURON_COUNT, cudaMemcpyHostToDevice);
cudaMemcpy(d_hiddenLevelFinishedFlag, h_hiddenLevelFinishedFlag, sizeof(unsigned int), cudaMemcpyHostToDevice);
//Grid and block sizing definitions
//
dim3 inputToHiddenGrid(HIDDEN_LEVEL_NEURON_COUNT,1,1);
dim3 inputToHiddenBlock(INPUT_COUNT,1,1);
int sharedMemSize1 = sizeof(float) * INPUT_COUNT;
dim3 hiddenToOutputGrid(OUTPUT_LEVEL_NEURON_COUNT,1,1);
dim3 hiddenToOutputBlock(HIDDEN_LEVEL_NEURON_COUNT,1,1);
int sharedMemSize2 = sizeof(float) * HIDDEN_LEVEL_NEURON_COUNT;
cudaThreadSynchronize();
//Warmup Run
//
generalPerceptron<INPUT_COUNT><<<inputToHiddenGrid,inputToHiddenBlock,sharedMemSize1>>>(d_inputVector, d_hiddenLevelWeightingMatrix, d_hiddenToOutputBuffer);
generalPerceptron<HIDDEN_LEVEL_NEURON_COUNT><<<hiddenToOutputGrid,hiddenToOutputBlock,sharedMemSize2>>>(d_hiddenToOutputBuffer,d_outputLevelWeightingMatrix,d_outputVector);
//Initialize hTimer
//
cutCreateTimer(&hTimer);
cutResetTimer(hTimer);
cutStartTimer(hTimer);
//Execute the kernel using the data we copied from our host allocated memory into the
//device global memory.
//
#ifdef PAUSE
getchar();
printf("Calling inputToHidden<<>>> -> hiddenToOutput<<<>>>\n");
#endif
int passCount;
for(passCount = 0; passCount < PASS_COUNT; passCount++){
generalPerceptron<INPUT_COUNT><<<inputToHiddenGrid,inputToHiddenBlock,sharedMemSize1>>>(d_inputVector, d_hiddenLevelWeightingMatrix, d_hiddenToOutputBuffer);
generalPerceptron<HIDDEN_LEVEL_NEURON_COUNT><<<hiddenToOutputGrid,hiddenToOutputBlock,sharedMemSize2>>>(d_hiddenToOutputBuffer,d_outputLevelWeightingMatrix,d_outputVector);
}
//CUT_CHECK_ERROR("Execution failed");
cudaThreadSynchronize();
cutStopTimer(hTimer);
//Capture the d_outputVector from the device global memory and then copy it back to
//the Host device, (CPU)
//
//For debug purposes, lets gather together all of our global data out of the device
//
cudaMemcpy(h_hiddenLevelWeightingMatrix,d_hiddenLevelWeightingMatrix, sizeof(float) * hiddenLevelWeightingMatrixSize, cudaMemcpyDeviceToHost);
cudaMemcpy(h_hiddenToOutputBuffer, d_hiddenToOutputBuffer, sizeof(float) * HIDDEN_LEVEL_NEURON_COUNT, cudaMemcpyDeviceToHost);
cudaMemcpy(h_outputLevelWeightingMatrix,d_outputLevelWeightingMatrix, sizeof(float) * outputLevelWeightingMatrixSize, cudaMemcpyDeviceToHost);
cudaMemcpy(h_outputVector, d_outputVector, sizeof(float) * OUTPUT_LEVEL_NEURON_COUNT, cudaMemcpyDeviceToHost);
cudaMemcpy(h_hiddenLevelFinishedFlag, d_hiddenLevelFinishedFlag, sizeof(unsigned int), cudaMemcpyDeviceToHost);
currentTime = cutGetTimerValue(hTimer);
#ifdef CHECK_OUTPUT
int j;
printf("[Run %d]: ",runCount);
for(j = 0; j < OUTPUT_LEVEL_NEURON_COUNT; j++){
if (h_outputVector[j] != DESIRED_RES){
localError++;
printf("*");
}
}
printf("\n");
#endif
#ifndef CHECK_OUTPUT
displayVector(h_outputVector,OUTPUT_LEVEL_NEURON_COUNT);
printf("Press any key to see hiddenToOutputBuffer");
getchar();
displayVector(h_hiddenToOutputBuffer,HIDDEN_LEVEL_NEURON_COUNT);
#endif
totalTime += currentTime;
minTime = minf(minTime,currentTime);
maxTime = maxf(maxTime,currentTime);
//Release
cutDeleteTimer(hTimer);
cudaFree(d_inputVector);
cudaFree(d_hiddenLevelWeightingMatrix);
cudaFree(d_hiddenToOutputBuffer);
cudaFree(d_outputLevelWeightingMatrix);
cudaFree(d_outputVector);
cudaFree(d_hiddenLevelFinishedFlag);
free(h_inputVector);
free(h_hiddenLevelWeightingMatrix);
free(h_hiddenToOutputBuffer);
free(h_outputLevelWeightingMatrix);
free(h_outputVector);
free(h_hiddenLevelFinishedFlag);
totalErrorCount += localError;
}
printf("Ran Propogate Test for %d Runs\n",runCount);
printf("Minimum Time: %f\n",minTime/(float)PASS_COUNT);
printf("Average Time: %f\n",(totalTime/runCount)/(float)PASS_COUNT);
printf("Maximum time: %f\n",maxTime/(float)PASS_COUNT);
printf("Overall Error Count: %d/%d (%f%)\n",totalErrorCount,OUTPUT_LEVEL_NEURON_COUNT*runCount,
(float)totalErrorCount/(float)(OUTPUT_LEVEL_NEURON_COUNT*runCount));
getchar();
displayVector(h_outputVector, OUTPUT_LEVEL_NEURON_COUNT);
CUT_EXIT(argc,argv);
}
CUDA Kernels
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
/*FOUND THE DEADLOCK ERROR:
For the first stage of the neural net, we CANNOT have a __synchthreads() for only
a specific number of threads within a single block: this is going to cause a deadlock
as the other threads are supposed to wait to arrive at a point that they can never
get to (having __syncthreads() within an if(threadIdx) conditional). To overcome this
we're going to have to make the hidden layer matrix conform to our sizing rules (256
threads/column) and simply pad our data.
*/
#define IDENTITY 0
#define SIGMOID 1
#define INPUT_COUNT 64
#define HIDDEN_LEVEL_NEURON_COUNT 256
#define OUTPUT_LEVEL_NEURON_COUNT 32
__device__ float
activationFunction (float in, int mode){
switch(mode){
case IDENTITY:
return in;
case SIGMOID:
//This exp function could be potentially taking 32 clock cycles
//It must be computed once for each neuron.
//Required, though :/
//
return 1/(1 - expf(-1.0*in));
}
return 0.0;
}
template <unsigned int inputCount>
__global__ void
generalPerceptron(float* g_inputVector, float* g_weightingMatrix,
float* g_outputVector){
extern __shared__ float sdata[];
unsigned int tid = threadIdx.x;
//This multiplacation of blockIdx.x and blockDim.x could potentially be
//taking 16 clock cycles instead of 4 clock cycles. That is a significant
//number of wasted clock cycles over the course of thousands of iterations.
//Perhaps this time could be reduced through use of the __mul24() function.
//
//RESULTS: useage of __mul24() versus a straight multiplcation makes no
//noticable difference overall. Disappointing.
unsigned int i = __mul24(blockIdx.x,blockDim.x) + tid;
sdata[tid] = g_weightingMatrix[i] * g_inputVector[tid];
__syncthreads();
if (inputCount >= 512) { if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads(); }
if (inputCount >= 256) { if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads(); }
if (inputCount >= 128) { if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads(); }
if (tid < 32)
{
if (inputCount >= 64) { sdata[tid] += sdata[tid + 32];}
if (inputCount >= 32) { sdata[tid] += sdata[tid + 16];}
if (inputCount >= 16) { sdata[tid] += sdata[tid + 8];}
if (inputCount >= 8) { sdata[tid] += sdata[tid + 4];}
if (inputCount >= 4) { sdata[tid] += sdata[tid + 2];}
if (inputCount >= 2) { sdata[tid] += sdata[tid + 1];}
}
__syncthreads();
if(tid == 0){
g_outputVector[blockIdx.x] = activationFunction(sdata[0],IDENTITY);
}
}